by
匯智軟件 發(fā)布時(shí)間:2016/11/8

1 Hadoop是什么����?
Google公司發(fā)表了兩篇論文:一篇論文是“The Google File System”��,介紹如何實(shí)現(xiàn)分布式地存儲(chǔ)海量數(shù)據(jù)����;另一篇論文是“Mapreduce:Simplified Data Processing on Large Clusters”,介紹如何對(duì)分布式大規(guī)模數(shù)據(jù)進(jìn)行處理��。Doug Cutting在這兩篇論文的啟發(fā)下�,基于OSS(Open Source software)的思想實(shí)現(xiàn)了這兩篇論文中的原理,從而Hadoop誕生了�����。
Hadoop是一種開(kāi)源的適合大數(shù)據(jù)的分布式存儲(chǔ)和處理的平臺(tái)����。作為一種大規(guī)模分布式數(shù)據(jù)處理平臺(tái),Hadoop已成為許多程序員的一項(xiàng)重要技能�。
2 Hadoop能夠做什么?
以下內(nèi)容有博友王路情整理�����。
大數(shù)據(jù)時(shí)代已經(jīng)到來(lái),給我們的生活��、工作�、思維方式都帶來(lái)變革。如何尋求大數(shù)據(jù)后面的價(jià)值���,既是機(jī)遇又是挑戰(zhàn)���。不管是金融數(shù)據(jù)、還是電商數(shù)據(jù)�、又還是社交數(shù)據(jù)、游戲數(shù)據(jù)… … 這些數(shù)據(jù)的規(guī)模�����、結(jié)構(gòu)���、增長(zhǎng)的速度都給傳統(tǒng)數(shù)據(jù)存儲(chǔ)和處理技術(shù)帶來(lái)巨大的考驗(yàn)���。幸運(yùn)的是,Hadoop的誕生和所構(gòu)建成的生態(tài)系統(tǒng)給大數(shù)據(jù)的存儲(chǔ)�、處理和分析帶來(lái)了曙光。
不管是國(guó)外的著名公司Google��、Yahoo!、微軟�����、亞馬遜�����、 EBay����、FaceBook���、Twitter�����、LinkedIn等和初創(chuàng)公司Cloudera�����、Hortonworks等�����,又還是國(guó)內(nèi)的著名公司中國(guó)移動(dòng)�、阿里巴巴、華為�、騰訊、百度���、網(wǎng)易���、京東商城等,都在使用Hadoop及相關(guān)技術(shù)解決大規(guī)?�;瘮?shù)據(jù)問(wèn)題��,以滿(mǎn)足公司需求和創(chuàng)造商業(yè)價(jià)值����。
例如:Yahoo! 的垃圾郵件識(shí)別和過(guò)濾、用戶(hù)特征建模系統(tǒng)����;Amazon.com(亞馬遜)的協(xié)同過(guò)濾推薦系統(tǒng);Facebook的Web日志分析���;Twitter����、LinkedIn的人脈尋找系統(tǒng);淘寶商品推薦系統(tǒng)�、淘寶搜索中的自定義篩選功能……這些應(yīng)用都使用到Hadoop及其相關(guān)技術(shù)。
“Hadoop能做什么��?” ��,概括如下:
1)搜索引擎:這也正是Doug Cutting設(shè)計(jì)Hadoop的初衷���,為了針對(duì)大規(guī)模的網(wǎng)頁(yè)快速建立索引;
2)大數(shù)據(jù)存儲(chǔ):利用Hadoop的分布式存儲(chǔ)能力�,例如數(shù)據(jù)備份、數(shù)據(jù)倉(cāng)庫(kù)等�����;
3)大數(shù)據(jù)處理:利用Hadoop的分布式處理能力�,例如數(shù)據(jù)挖掘、數(shù)據(jù)分析等��;
4)科學(xué)研究:Hadoop是一種分布式的開(kāi)源框架�����,對(duì)于分布式系統(tǒng)有很大程度地參考價(jià)值。
3 Hadoop的三種模式
Hadoop有三種不同的模式操作�,分別為單機(jī)模式、偽分布模式和全分布模式��。每種模式的詳細(xì)介紹以及單機(jī)模式的安裝請(qǐng)閱讀我之前的博客:[Hadoop] 在Ubuntu系統(tǒng)上一步步搭建Hadoop(單機(jī)模式)����,偽分布式模式和全分布式模式的相關(guān)操作請(qǐng)見(jiàn)王路情的博客。
4 Hadoop核心之分布式文件系統(tǒng)HDFS
Hadoop分布式文件系統(tǒng)(Hadoop Distributed File System��,簡(jiǎn)稱(chēng)HDFS)是Hadoop的核心模塊之一����,它主要解決Hadoop的大數(shù)據(jù)存儲(chǔ)問(wèn)題,其思想來(lái)源與Google的文件系統(tǒng)GFS��。HDFS的主要特點(diǎn):
保存多個(gè)副本���,且提供容錯(cuò)機(jī)制��,副本丟失或宕機(jī)自動(dòng)恢復(fù)����。默認(rèn)存3份����。
運(yùn)行在廉價(jià)的機(jī)器上����。
適合大數(shù)據(jù)的處理�。HDFS默認(rèn)會(huì)將文件分割成block,64M為1個(gè)block�。然后將block按鍵值對(duì)存儲(chǔ)在HDFS上,并將鍵值對(duì)的映射存到內(nèi)存中�。如果小文件太多,那內(nèi)存的負(fù)擔(dān)會(huì)很重���。
HDFS中的兩個(gè)重要角色:
[Namenode]
1)管理文件系統(tǒng)的命名空間。
2)記錄 每個(gè)文件數(shù)據(jù)快在各個(gè)Datanode上的位置和副本信息��。
3)協(xié)調(diào)客戶(hù)端對(duì)文件的訪(fǎng)問(wèn)����。
4)記錄命名空間內(nèi)的改動(dòng)或者空間本省屬性的改動(dòng)。
5)Namenode 使用事務(wù)日志記錄HDFS元數(shù)據(jù)的變化��。使用映像文件存儲(chǔ)文件系統(tǒng)的命名空間�����,包括文件映射,文件屬性等���。
從社會(huì)學(xué)來(lái)看�,Namenode是HDFS里面的管理者�,發(fā)揮者管理、協(xié)調(diào)��、操控的作用��。
[Datanode]
1)負(fù)責(zé)所在物理節(jié)點(diǎn)的存儲(chǔ)管理�。
2)一次寫(xiě)入,多次讀?�。ú恍薷模?。
3)文件由數(shù)據(jù)庫(kù)組成,一般情況下���,數(shù)據(jù)塊的大小為64MB�����。
4)數(shù)據(jù)盡量散步到各個(gè)節(jié)點(diǎn)�����。
從社會(huì)學(xué)的角度來(lái)看�����,Datanode是HDFS的工作者����,發(fā)揮按著Namenode的命令干活,并且把干活的進(jìn)展和問(wèn)題反饋到Namenode的作用��。
客戶(hù)端如何訪(fǎng)問(wèn)HDFS中一個(gè)文件呢�?具體流程如下:
1)首先從Namenode獲得組成這個(gè)文件的數(shù)據(jù)塊位置列表。
2)接下來(lái)根據(jù)位置列表知道存儲(chǔ)數(shù)據(jù)塊的Datanode����。
3)最后訪(fǎng)問(wèn)Datanode獲取數(shù)據(jù)。
注意:Namenode并不參與數(shù)據(jù)實(shí)際傳輸���。
數(shù)據(jù)存儲(chǔ)系統(tǒng),數(shù)據(jù)存儲(chǔ)的可靠性至關(guān)重要����。HDFS是如何保證其可靠性呢?它主要采用如下機(jī)理:
1)冗余副本策略,即所有數(shù)據(jù)都有副本���,副本的數(shù)目可以在hdfs-site.xml中設(shè)置相應(yīng)的復(fù)制因子���。
2)機(jī)架策略,即HDFS的“機(jī)架感知”����,一般在本機(jī)架存放一個(gè)副本,在其它機(jī)架再存放別的副本�,這樣可以防止機(jī)架失效時(shí)丟失數(shù)據(jù),也可以提供帶寬利用率����。
3)心跳機(jī)制,即Namenode周期性從Datanode接受心跳信號(hào)和快報(bào)告���,沒(méi)有按時(shí)發(fā)送心跳的Datanode會(huì)被標(biāo)記為宕機(jī)��,不會(huì)再給任何I/O請(qǐng)求�,若是Datanode失效造成副本數(shù)量下降�,并且低于預(yù)先設(shè)置的閾值,Namenode會(huì)檢測(cè)出這些數(shù)據(jù)塊���,并在合適的時(shí)機(jī)進(jìn)行重新復(fù)制�。
4)安全模式,Namenode啟動(dòng)時(shí)會(huì)先經(jīng)過(guò)一個(gè)“安全模式”階段��。
5)校驗(yàn)和�,客戶(hù)端獲取數(shù)據(jù)通過(guò)檢查校驗(yàn)和,發(fā)現(xiàn)數(shù)據(jù)塊是否損壞�����,從而確定是否要讀取副本�����。
6)回收站���,刪除文件����,會(huì)先到回收站/trash�,其里面文件可以快速回復(fù)。
7)元數(shù)據(jù)保護(hù)�,映像文件和事務(wù)日志是Namenode的核心數(shù)據(jù)�����,可以配置為擁有多個(gè)副本。
8)快照�����,支持存儲(chǔ)某個(gè)時(shí)間點(diǎn)的映像�����,需要時(shí)可以使數(shù)據(jù)重返這個(gè)時(shí)間點(diǎn)的狀態(tài)����。
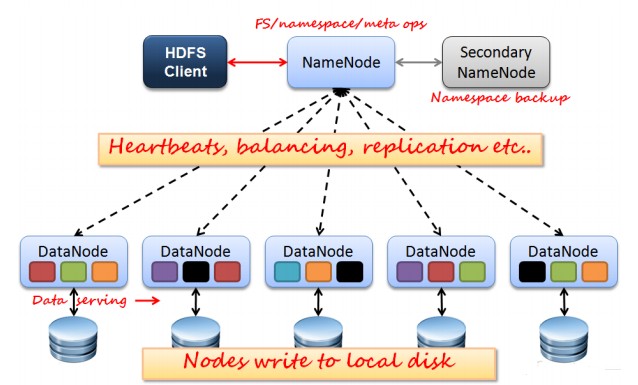
如上圖所示,HDFS也是按照Master和Slave的結(jié)構(gòu)���。分NameNode��、SecondaryNameNode����、DataNode這幾個(gè)角色�。
NameNode:是Master節(jié)點(diǎn),是大領(lǐng)導(dǎo)�。管理數(shù)據(jù)塊映射���;處理客戶(hù)端的讀寫(xiě)請(qǐng)求;配置副本策略�;管理HDFS的名稱(chēng)空間;
SecondaryNameNode:是一個(gè)小弟��,分擔(dān)大哥namenode的工作量����;是NameNode的冷備份;合并fsimage和fsedits然后再發(fā)給namenode�。
DataNode:Slave節(jié)點(diǎn),奴隸�,干活的。負(fù)責(zé)存儲(chǔ)client發(fā)來(lái)的數(shù)據(jù)塊block���;執(zhí)行數(shù)據(jù)塊的讀寫(xiě)操作��。
熱備份:b是a的熱備份��,如果a壞掉����。那么b馬上運(yùn)行代替a的工作���。
冷備份:b是a的冷備份����,如果a壞掉�。那么b不能馬上代替a工作。但是b上存儲(chǔ)a的一些信息���,減少a壞掉之后的損失�。
fsimage:元數(shù)據(jù)鏡像文件(文件系統(tǒng)的目錄樹(shù)���。)
edits:元數(shù)據(jù)的操作日志(針對(duì)文件系統(tǒng)做的修改操作記錄)
namenode內(nèi)存中存儲(chǔ)的是=fsimage+edits���。
SecondaryNameNode負(fù)責(zé)定時(shí)默認(rèn)1小時(shí),從namenode上����,獲取fsimage和edits來(lái)進(jìn)行合并,然后再發(fā)送給namenode�。減少namenode的工作量。
有關(guān)HDFS詳細(xì)的寫(xiě)操作和讀操作請(qǐng)見(jiàn):老魏的博客���。
有關(guān)HDFS的優(yōu)缺點(diǎn)介紹請(qǐng)見(jiàn):蝦皮工作室�����。
有一個(gè)關(guān)于HDFS工作原理的漫畫(huà)版本�,請(qǐng)見(jiàn)這里:HDFS漫畫(huà)詳解。
5 Hadoop核心之MapReduce
上部分提到Hadoop存儲(chǔ)大數(shù)據(jù)的核心模塊HDFS����,這一部分介紹Hadoop處理大數(shù)據(jù)部分的核心模塊MapReduce。
Apache Foundation對(duì)MapReduce的介紹:“Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.”
由此可知�����,Hadoop核心之MapReduce是一個(gè)軟件框架���,基于該框架能夠容易地編寫(xiě)應(yīng)用程序�,這些應(yīng)用程序能夠運(yùn)行在由上千個(gè)商用機(jī)器組成的大集群上�,并以一種可靠的,具有容錯(cuò)能力的方式并行地處理上TB級(jí)別的海量數(shù)據(jù)集�����。這個(gè)定義里面有著這些關(guān)鍵詞��,一是軟件框架�����,二是并行處理,三是可靠且容錯(cuò)����,四是大規(guī)模集群��,五是海量數(shù)據(jù)集����。因此,對(duì)于MapReduce�,可以簡(jiǎn)潔地認(rèn)為,它是一個(gè)軟件框架���,海量數(shù)據(jù)是它的“菜”�,它在大規(guī)模集群上以一種可靠且容錯(cuò)的方式并行地“烹飪這道菜”���。
MapReduce主要是用于解決Hadoop大數(shù)據(jù)處理的���。所謂大數(shù)據(jù)處理,即以?xún)r(jià)值為導(dǎo)向�,對(duì)大數(shù)據(jù)加工���、挖掘和優(yōu)化等各種處理。
MapReduce擅長(zhǎng)處理大數(shù)據(jù)�,它為什么具有這種能力呢?這可由MapReduce的設(shè)計(jì)思想發(fā)覺(jué)���。MapReduce的思想就是“分而治之”�����。Mapper負(fù)責(zé)“分”�,即把復(fù)雜的任務(wù)分解為若干個(gè)“簡(jiǎn)單的任務(wù)”來(lái)處理��?���!昂?jiǎn)單的任務(wù)”包含三層含義:一是數(shù)據(jù)或計(jì)算的規(guī)模相對(duì)原任務(wù)要大大縮小�����;二是就近計(jì)算原則��,即任務(wù)會(huì)分配到存放著所需數(shù)據(jù)的節(jié)點(diǎn)上進(jìn)行計(jì)算;三是這些小任務(wù)可以并行計(jì)算�����,彼此間幾乎沒(méi)有依賴(lài)關(guān)系�。Reducer負(fù)責(zé)對(duì)map階段的結(jié)果進(jìn)行匯總。至于需要多少個(gè)Reducer�,用戶(hù)可以根據(jù)具體問(wèn)題,通過(guò)在mapred-site.xml配置文件里設(shè)置參數(shù)mapred.reduce.tasks的值����,缺省值為1�����。
MapReduce的工作機(jī)制如圖所示:

MapReduce的整個(gè)工作過(guò)程如上圖所示��,它包含如下4個(gè)獨(dú)立的實(shí)體:
1)客戶(hù)端��,用來(lái)提交MapReduce作業(yè)�。
2)jobtracker,用來(lái)協(xié)調(diào)作業(yè)的運(yùn)行�����。
3)tasktracker,用來(lái)處理作業(yè)劃分后的任務(wù)��。
4)HDFS���,用來(lái)在其它實(shí)體間共享作業(yè)文件�����。
MapReduce整個(gè)工作過(guò)程有序地包含如下工作環(huán)節(jié):
1)作業(yè)的提交
2)作業(yè)的初始化
3)任務(wù)的分配
4)任務(wù)的執(zhí)行
5)進(jìn)程和狀態(tài)的更新
6)作業(yè)的完成
有關(guān)MapReduce的詳細(xì)工作細(xì)節(jié)�����,請(qǐng)見(jiàn):《Hadoop權(quán)威指南(第二版)》第六章MapReduce工作機(jī)制�����?!?/span>
6 參考內(nèi)容
[1] The Google File System
[2] MapReduce:Simplified Data Processing on Large Clusters
[3] Hadoop in Action
[4] 王路情博客
[5] 《Hadoop權(quán)威指南(第二版)》
出處:http://www.cnblogs.com/maybe2030/p/4593190.html#_label0 作者:Poll的筆記

